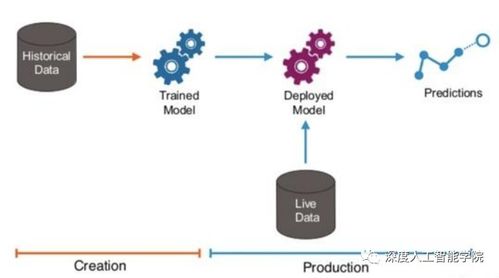
人工智能應(yīng)用軟件項目的開發(fā)是一個系統(tǒng)化的工程過程,它結(jié)合了傳統(tǒng)軟件工程方法與AI特有的模型開發(fā)、數(shù)據(jù)處理和迭代優(yōu)化特性。以下是典型的人工智能項目開發(fā)流程概述:
1. 需求分析與目標(biāo)確定
在項目啟動階段,團(tuán)隊需要與利益相關(guān)者充分溝通,明確業(yè)務(wù)需求、功能目標(biāo)和期望效果。包括確定AI應(yīng)用的場景(如推薦系統(tǒng)、圖像識別、自然語言處理等)、性能指標(biāo)(如準(zhǔn)確率、響應(yīng)時間)以及約束條件(如預(yù)算、時間、資源)。在這一階段,還需要評估項目可行性,判斷數(shù)據(jù)可用性、技術(shù)可行性和商業(yè)價值。
2. 數(shù)據(jù)收集與預(yù)處理
數(shù)據(jù)是AI項目的核心。團(tuán)隊需要收集相關(guān)數(shù)據(jù)集,可能包括公開數(shù)據(jù)集、企業(yè)內(nèi)部數(shù)據(jù)或通過爬蟲等方式獲取的外部數(shù)據(jù)。隨后進(jìn)行數(shù)據(jù)清洗,處理缺失值、異常值和重復(fù)數(shù)據(jù),并進(jìn)行標(biāo)注(對于監(jiān)督學(xué)習(xí)任務(wù))。數(shù)據(jù)預(yù)處理還包括特征工程,即提取、選擇和轉(zhuǎn)換特征,以提升模型性能。
3. 模型選擇與設(shè)計
根據(jù)任務(wù)類型(如分類、回歸、聚類),選擇合適的算法和模型架構(gòu)。例如,對于圖像處理,可能選擇卷積神經(jīng)網(wǎng)絡(luò)(CNN);對于序列數(shù)據(jù),可能采用循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)或Transformer。在這一階段,團(tuán)隊可能設(shè)計多個候選模型,并規(guī)劃實驗以比較性能。
4. 模型訓(xùn)練與驗證
使用預(yù)處理后的數(shù)據(jù)對模型進(jìn)行訓(xùn)練。訓(xùn)練過程通常涉及劃分訓(xùn)練集、驗證集和測試集,以評估模型的泛化能力。團(tuán)隊需要調(diào)優(yōu)超參數(shù)(如學(xué)習(xí)率、批量大小),并使用驗證集監(jiān)控模型性能,防止過擬合或欠擬合。常見的評估指標(biāo)包括準(zhǔn)確率、精確率、召回率和F1分?jǐn)?shù)。
5. 模型評估與優(yōu)化
在測試集上對模型進(jìn)行最終評估,確保其滿足預(yù)設(shè)的性能標(biāo)準(zhǔn)。如果性能不足,團(tuán)隊需要返回前幾個步驟進(jìn)行迭代優(yōu)化,可能包括重新設(shè)計特征、調(diào)整模型結(jié)構(gòu)或增加數(shù)據(jù)量。還需考慮模型的魯棒性、可解釋性和公平性。
6. 部署與集成
將訓(xùn)練好的模型部署到生產(chǎn)環(huán)境,通常涉及模型轉(zhuǎn)換(如轉(zhuǎn)換為ONNX格式)、性能優(yōu)化(如量化、剪枝)和容器化(如使用Docker)。模型需要集成到現(xiàn)有軟件系統(tǒng)中,并通過API或微服務(wù)提供接口。部署過程中,還需設(shè)置監(jiān)控機制,以跟蹤模型在生產(chǎn)環(huán)境中的表現(xiàn)。
7. 維護(hù)與迭代
AI應(yīng)用上線后,需要持續(xù)監(jiān)控其性能,處理數(shù)據(jù)漂移和概念漂移問題。團(tuán)隊?wèi)?yīng)定期收集新數(shù)據(jù),重新訓(xùn)練模型以保持其準(zhǔn)確性。同時,根據(jù)用戶反饋和業(yè)務(wù)變化,對應(yīng)用進(jìn)行功能更新和優(yōu)化,形成閉環(huán)迭代流程。
人工智能應(yīng)用軟件開發(fā)是一個循環(huán)迭代的過程,強調(diào)數(shù)據(jù)驅(qū)動、實驗驗證和持續(xù)改進(jìn)。成功的關(guān)鍵在于跨學(xué)科團(tuán)隊的合作,包括數(shù)據(jù)科學(xué)家、軟件工程師和領(lǐng)域?qū)<业木o密協(xié)作,以確保項目從概念到部署的順利推進(jìn)。